DeepSeek
DeepSeek’s breakthrough on cost challenges the “bigger is better” narrative that has driven the A.I. arms race in recent years by showing that relatively small models, when trained properly, can match or exceed the performance of much bigger models.
That, in turn, means that A.I. companies may be able to achieve very powerful capabilities with far less investment than previously thought. And it suggests that we may soon see a flood of investment into smaller A.I. start-ups, and much more competition for the giants of Silicon Valley. (Which, because of the enormous cost of training their models, have mostly been competing with each other until now)
There are other, more technical reasons that everyone in Silicon Valley is paying attention to DeepSeek. In the research paper, the company reveals some details about how R1 was actually built, which include some cutting-edge techniques in model distillation. (Basically ones, making them cheaper to run without losing much in the way of performance)
DeepSeek also included details that suggested that it had not been as hard as previously thought to convert a “vanilla” A.I. language model into a more sophisticated reasoning model, by applying a technique known as reinforcement learning on top of it.
The most surprising part of DeepSeek-R1 is that it only takes ~800k samples of ‘good’ RL reasoning to convert other models into RL-reasoners. Now that DeepSeek-R1 is available people will be able to refine samples out of it to convert any other model into an RL reasoner.
This is a big deal because it says that if you want to control AI systems you need to not only control the basic resources(e.g, compute, electricity), but also the platforms the systems are being served on(e.g., proprietary websites) so that you don’t leak the really valuable stuff – samples including chains of thought from reasoning models.
If you’re Meta – the only U.S. tech giant that releases its models as free open-source software – what prevents Deep Seek or another start-up from simply taking your models, which you spent billions of dollars on, and distilling them into smaller, cheaper models that they con offer for pennies?
Aha Moment of DeepSeek-R1-Zero
This aha moment underscores the power and beauty of reinforcement learning: rather than explicitly teaching the model on how to solve a problem, we simply provide it with the right incentives, and it autonomously develops advanced problem-solving strategies. The “aha moment” serves as a powerful reminder of the potential of RL to unlock new levels of intelligence in artificial systems, paving the way for more autonomous and adaptive models in the future.
Description without jargon
R1 surfed the web endlessly (pre-training) then read a reasoning manual made by humans(SFT – supervised fine-tuning), and finally did some self-experimentation (RL + TTC – test-time compute). R1-Zero, in contrast, didn’t read any manuals. They pre-trained R1-Zero on tons of web data and immediately after sent it to the RL phase: “Now go figure out how to reason yourself.”
DeepSeek’s approach to R1 and R1-Zero is reminiscent of DeepMind’s approach to AlphGo and AlphGo Zero. DeepMind did something similar to go from AlphGo to AlphaGo Zero in 2016-2017. AlphaGo learned to play Go by knowing the rules and learning from millions of human matches but then, a year later, decided to teach AlphaGo Zero without any human data, just the rules. And it destroyed AlphaGo. Unfortunately, open-ended reasoning has proven harder than Go; R1-Zero is slightly worse than R1 and has some issues like poor readability (besides, both still rely heavily on vast amounts of human-crated data in their base model – a far cry from an AI capability of rebuilding human civilization using nothing more than the laws of physics).
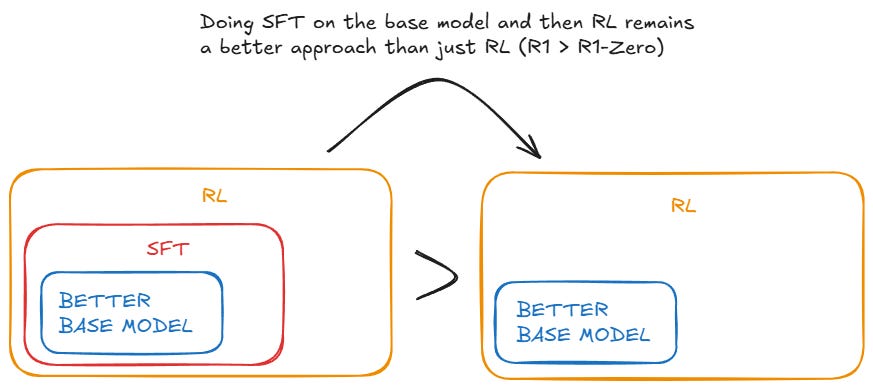
Better base models + distillation + RL wins
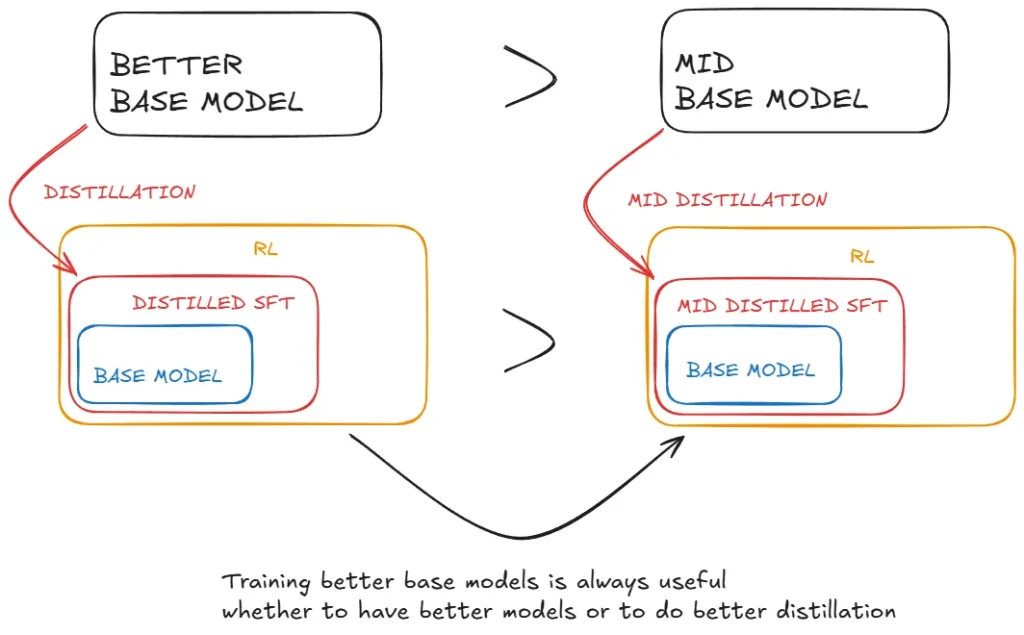
While distillation strategies are both economical and effective, advancing beyond the boundaries of intelligence may still require more powerful base models and larger-scale reinforcement learning.
2025.1.28