Java Virtual Threads and Enterprise Scalability
Java언어로 Enterprise 어플리케이션을 작성하거나 기존의 Enterprise 어플리케이션이 있다면 Virtual Thread에 관심을 둘 필요가 있다. Virtual Thread는 Java 21에 소개된 새로운 기능으로 어플리케이션의 확장성(Scalability)를 획기적으로 높여주며 프로젝트에 드는 비용을 줄여 준다. 이 문서는 문제의 근간을 들여다 봄으로써 Virtual Thread를 활용할 경우 왜 확장성이 개선 되는지를 설명하고자 한다.
Platform Thread
Java 21 이전에 구현된 Thread를 Platform Thread 라고하며 근본적으로 OS(Operating System) Thread를 Wrapping한 형태로 구현되어 있다. 따라서 Platform Thread와 OS Thread간의 관계는 1:1 매핑이라고 생각하면 된다.

위 그림을 보면 가장 밑 부분은 CPU Core 를 나타내며 OS 레벨에서는 OS Thread가 있고 JVM에 있는 Platform Thread는 OS Thread와 1:1 관계를 가진다. Platform Thread에서 실행되는 코드는 OS Thread 상에서 동작하며 이는 결국 가용한 CPU Core들 중 하나를 이용하는 형태가 된다.
Limitations of Platform Threads
JVM에서는 제한된 수의 Platform Thread만 생성 가능하다. 이는 개별 Platform Thread가 디폴트 1MB의 메모리를 차지하기 때문이며 이로 인해 값비싼 자원으로 인식되기도 한다. OS는 일반적으로 하나의 프로세스를 위해 실행할 수 있는 OS Thread 개수에 제한을 두고 있다. JVM 내에서 생성할 수 있는 Platform Thread의 개수는 궁극적으로 JVM이 관리하는 메모리와 OS에 의존하게 된다. 예를들면 애플의 Mac Mini에서 1G 메모리로 실행하는 어플리케이션에서는 약 4,000개의 Platform Thread를 생성할 수 있다.
이는 Enterprise 어플리케이션의 확장성에는 좋은 소식이 못된다. 왜나하면 일반적으로 어플리케이션 서버에서 개별 사용자 Request는 하나의 Java Platform Thread와 매핑되며 이 User Request의 실행이 완전히 끝날 때까지 해당 Thread는 반환되지 않기 때문이다. 아래 그림은 Enterprise 어플리케이션의 전형적인 예를 보여준다. 여기서 Web 어플리케이션은 모든 User Request를 Platform Thread로 처리하고 있다 (빨간색의 세로 방향 화살표는 Platform Thread를 나타냄). 이는 Thread Per Request 모델로 Tomcat과 같은 대부분의 Blocking 어플리케이션 서버에서 적용되고 있다.

이런 전형적인 Web 어플리케이션은 User Request를 처리하기 위해 정해진 개수 이상으로 Platform Thread를 생성할 수 없음을 의미한다. 그렇지 않다면 메모리 부족 또는 그외 다른 리소스가 부족해지는 상황을 맞이하게 될 것이다. 따라서 이런 문제를 해결하기 위해 일반적으로 어플리케이션 서버는 Thread Pool을 이용하여 Thread를 Pooling하도록 처리한다.
Tomcat 서버는 default로 200개의 Thread를 Pool로 생성한다. 이는 동시 접속자 수가 200명이 될 때까지는 문제없이 동작한다. 그러나 동시 접속자 300명이 서버에 몰리면 어떻게 될까? 사용자 Request 중 200개는 Thread Pool의 Thread에 의해 처리될 것이지만 나머지 100개는 자기 차례가 될 때까지 기다려야 하며 이는 성능 문제를 야기시킨다. 대부분의 Enterprise 어플리케이션에서 CPU 활용율과 메모리는 이 상황에서도 임계치에 도달하지 않는다. 요약하면 확장성 이슈를 발생시키는 요인은 CPU 또는 메모리가 아닌 Thread의 개수의 제약으로 인한 것일 수 있다.
Scaling to Large Number of Users
많은 수의 사용자를 처리할 수 있도록 확장할 수 있는 한가지 방법은 서버 장비에 메모리나 CPU 같은 리소스를 추가하는 것이다. 이렇게 하는 것을 Vertical Scaling이라고 한다.

또는, 어플리케이션 인스턴스 수를 늘린 후 들어오는 요청을 Load Balancer가 이들 인스턴스로 Routing 하도록 처리할 수 있다. 이 같은 방법을 Horizontal Scaling이라고 한다.

많은 사용자를 처리하도록 Enterprise 어플리케이션을 확장하고자 할 경우 다음과 같이 3가지의 방법으로 접근할 수 있다.
- 최적의 사용자 수를 처리를 의한 개별 Instance 최적화
- Vertical Scaling
- Horizontal Scaling
이 방법들은 한가지 중대한 문제점을 내포하고 있다. Horizontal과 Vertical Scaling을 활용할 경우 프로젝트 비용이 증가한다. 왜냐하면 장비와 리소스를 대여 또는 구매를 해야하기 때문이다. 한가지 활용할 수 있는 방법으로 Horizontal과 Vertical Scaling은 적게하면서 개별 Instance를 더욱 최적화 하는 것이다.
자 그럼, 확장성 문제가 발생하는 그 근간을 들여다 봄으로써 최적화 하는 방법에 대해 알아보자.
Blocking in Platform Threads
구체적인 예를 활용하여 Platform Thread가 동작할 때 어떤 일이 발생되는지 살펴보자. 아래 그림은 Platform Thread에 의해 처리되는 User Request를 보여주며 이때 이 Platform Thread는 Thread Pool에서 가져온 것으로 보면 된다.

User Request는 DB에서 데이터를 읽어오고 micro service 1 에서 그 외의 정보를 얻어온 다음 최종 결과를 반환한다. Thread가 수행한 CPU연산은 녹색으로 IO연산은 붉은색으로 표시했다. Thread는 IO 동작을 대기하는 동안에 멈춘 상태로 있어 다른 User Request를 처리할 수가 없다. IO 동작이 집약적인 어플리케이션은 쓰레드가 대부분 IO 동작 대기상태로 소비하게 된다. 따라서 Platform Thread는 user request가 모두 종료할 때까지 대기상태로 있어야 된다.
간단히 말하면 필요 이상으로 오랫동안 쓰레드를 잡고 있기 때문에 이는 확장성을 저해하는 근본적인 원인이 된다.
이런 문제로 인해 Reactive Framework이라는 다양한 형태의 non blocking 해결책들이 나타나게 된다. Spring Boot는 Spring WebFlux라는 이름의 온전한 스택으로 구성되며 이는 Project Reactor라는 Reactive library를 기반으로 한다. 그러나 non blocking IO의 프로그래밍 모델은 직관적이지가 않다. 프로그래머들은 일반적인 프로그래밍 스타일인 imperative 형태에서 reactive 형태로 개발 스타일에 변화를 줘야 한다. 이런 변화를 맞이하면 개발자는 실수를 한다거나 디버깅에 어려움을 겪을 수 있다.
이와 같은 확장성 문제 해결을 위한 일환으로 2018년 자바 엔지니어들은 Project Loom이라는 프로젝트를 출범시킨다. 이 당시 Fiber(섬유)라는 이름으로 고안해 낸 것이 지금에 와서 Virtual Thread라 불리고 있다.
Virtual Threads to the rescue
JVM에서 Virtual Thread는 Thread 클래스의 경량화된 구현체이다. Virtual Thread를 생성하는 것은 String 객체 생성만큼 빠르며 Platform Thread와 달리 값비싼 자원도 아니다. 사실 JVM에서 수 백만개의 Virtual Thread를 생성 하더라도 서버는 다운되지 않는다. 현재로서는 단지 Virtual Thread를 IO 오퍼레이션 동안 주요 자원을 점유하지 않는다와 같은 장점을 가진 Thread정도로 생각 하자.
아래에 Virtual Thread에서 실행되는 handleRequest() 메소드 예제가 있다.
// Start a new Virtual Thread. No name is associated with thread
Thread thread = Thread.startVirtualThread(() -> handleUserRequest())하지만 막후에서는 Virtual Thread가 어떻게 동작할까?
CPU관련 연산을 위해서는 실질적으로 Platform Thread를 이용하고 IO 오퍼레이션 동안에는 어떠한 중요한 자원도 점유하지 않고 대기 상태를 유지한다. 아래 그림에서와 같이 Virtual Thread에서 실행되는 단순한 사용자 요청(request)을 한 번 생각해 보자.
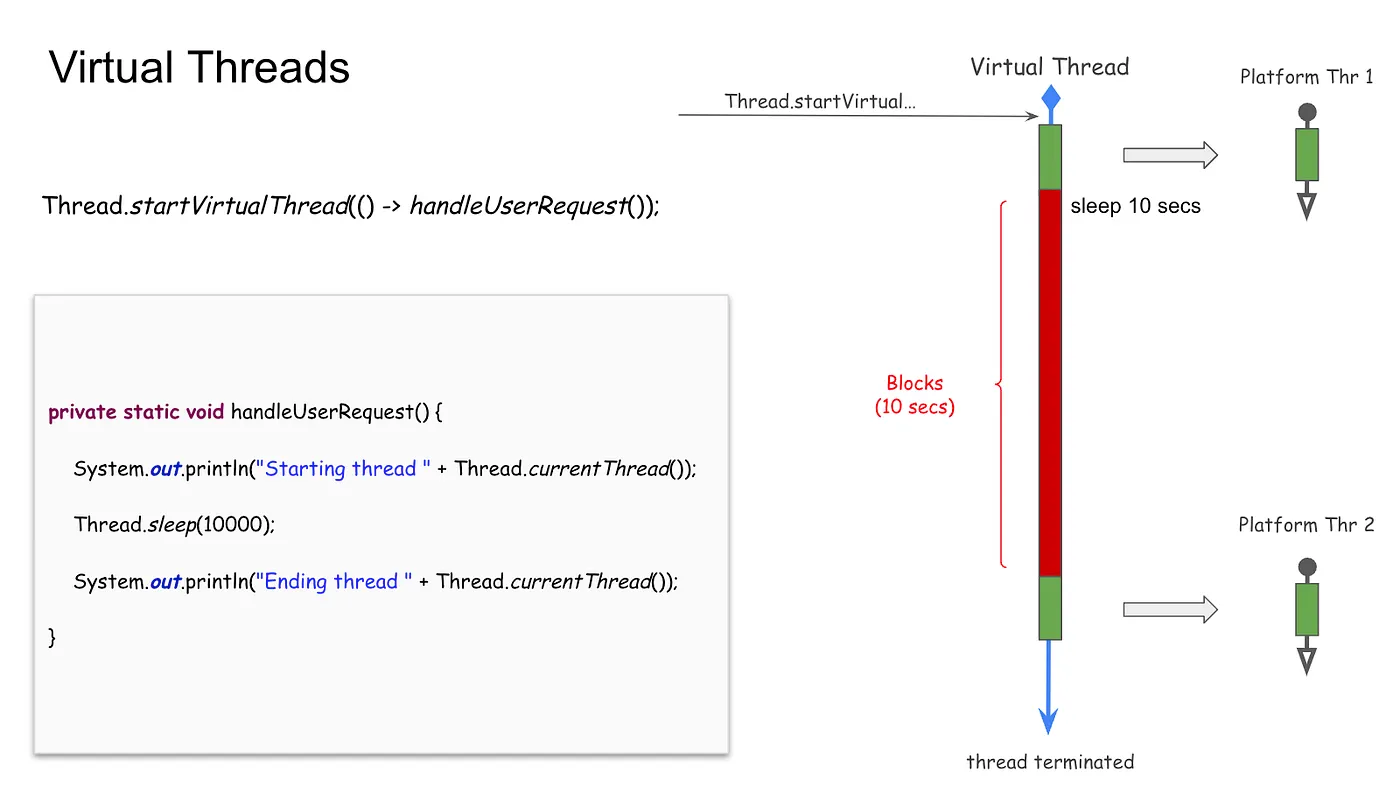
핵심적으로, Request 처리를 위한 CPU 오퍼레이션 동안 Virtual Thread는 Job을 수행하기 위해 기존의 Fork Join Pool로부터 Platform Thread를 사용하고 IO 오퍼레이션을 수행하는 동안에는 – 위 그림에서의 경우 sleep() 메소드. – Platform Thread가 다시 Pool로 반환된다. Virtual Thread가 CPU 오퍼레이션을 하도록 도와주는 Platform Thread는 Carrier Thread라도도 불린다. 여기서는 Carrier Thread와 Platform Thread를 동일한 Thread를 지칭하는 것으로 한다. Sleep 모드에서 깨어난 이후에도 Virtual Thread는 CPU 오퍼레이션을 수행하기 위해 또 다른 Carrier Thread를 선택해 가는 과정을 계속 이어간다. 사실, Virtual Thread는 사용자 Request를 처리함에 있어 필요한 CPU 오퍼레이션을 수행하기 위해 다수의 Carrier Thread를 사용하는 형태가 될 것이다. 위의 예제에서 보면 다른 라인에 출력되는 두 개의 Thread 정보는 서로 다른 형태를 가진다. 이때 출력을 보면 동일한 id의 Virtual Thread라 하더라도 서로 다른 Carrier Thread가 사용됨을 확인할 수 있다.
IO 오퍼레이션 시작 시점에 Carrier Thread를 놔줘야 한다는 것을 Virtual Thread는 어떻게 알까?
이 부분이 JVM에서 Virtual Thread 상의 코드가 IO 오퍼레이션을 수행할 경우 Carrier Thread는 반환되어야 한다는 것을 처리하기 위해 Java 엔지니어들이 이 두 영역을 오가면서 고심을 많이 했던 영역이다. IO 오퍼레이션으로는 파일 처리, Socket 읽기/쓰기, Locking 등이 있다. 그러나 자바 개발자들은 이제 이런 IO 오퍼레이션에 대한 고민이 필요 없게 되었다. 이는 자바 개발자들에게 큰 장점을 제공한다. 왜냐하면 핵심적인 것으로 개발 스타일에 변화를 주지 않으면서 공짜로 non blocking 기능을 적용할 수 있기 때문이다. 예전과 같이 동일한 형태의 절차적인 개발 스타일, 동일한 형태의 예외처리, 그리고 동일한 디버깅 기능을 이용할 수 있게 되는 것이다.
너무나 큰 장점을 얻게 되는 것이다!
Virtual Thread 생성
앞에서 설명했던 것처럼, Virtual Thread는 JVM내에서의 완전히 새로운 쓰레드 구현체이며 Platform Thread 처럼 많은 자원을 소모하지도 않는다. Virtual Thread는 기존의 Thread 클래스를 확장하므로 프로그래밍 모델은 아주 심플하다. 즉 기존의 Platform Thread와 동일한 형태를 유지한다. 그러나 확장성 측면에서 보면 그 결과는 본질적으로 다르다.
다음은 Virtual Thread를 시작하기 위한 몇 가지 방법을 보여 준다.
1. 아래 예제에서 handleUserRequest() 는 Virtual Thread상에서 동작한다.
// Start a new Virtual Thread. No name is associated with thread
Thread thread = Thread.startVirtualThread(() -> handleUserRequest())2. 아래 예제는 Virtual Thread에 이름을 설정하고 handleUserRequest() 가 동작되는 것을 보여 준다.
// Start a new Virtual Thread with a name ‘userthread’
Thread vThread = Thread.ofVirtual()
.name("userthread")
.start(() -> handleUserRequest());3. 아래 예제는 쓰레드를 생성하기 위해 Virtual Thread Factory가 이용 되었다.
// Create Virtual Threads from a Thread factory
ThreadFactory factory
= Thread.ofVirtual().name("userthread-", 0).factory();
// Thread name is userthread-0
Thread vThread1 = factory.newThread(() -> handleUserRequest());
vThread1.start();
// Thread name is userthread-1
Thread vThread2 = factory.newThread(() -> handleUserRequest());
vThread2.start();4. 아래 예제에서는 태스크(task)를 Thread로 전달하기 위해 Virtual Thread Per Task Executor가 이용 되었다. 여기서 ExecutorService를 이용하긴 하지만 실질적인 Virtual Thread 풀링(Pooling)은 아니다. task가 Executor Service에 전달되면 이 task를 실행하기 위해 새로운 Virtual Thread가 생성된다. 매우 빠르게 생성되고 Pool의 필요성이 낮기 때문에 Virtual Thread를 풀링(Pooling)한다는 것은 좋은 생각이 못된다.
// Submit two tasks to an Executor Service which uses Virtual Threads
try (var service = Executors.newVirtualThreadPerTaskExecutor()) {
service.submit(() -> handleUserRequest());
service.submit(() -> handleUserRequest());
}Virtual Thread 가 생성되면, 일반적인 Thread 객체에 있는 모든 메소드들은 Virtual Thread에도 동일하게 적용된다. Platform Thread처럼 Virtual Thread는 Thread Local과 Inheritable Thread Local과도 같이 사용 가능하다. 그러나 Virtual Thread는 항상 Daemon 쓰레드라는 것을 명심할 필요가 있다.
JVM 내부에서의 Virtual Thread
아래 그림은 JVM 내부에서의 Virtual Thread를 나타낸다.

개별 Virtual Thread는 한 번에 하나씩이긴 하지만 동작 중에 다수의 Platform Thread와 매핑될 수 있다. Virtual Thread가 여러 개의 CPU 연산을 수행한다고 생각해 보면 이들 각각의 연산은 서로 다른 Carrier Thread에 의해 실행될 수 있다.
Application Server 상에서의 Virtual Thread
Application Server 내에서 Virtual Thread를 실질적으로 어떻게 이용할 수 있을까? 여기서 핵심은 사용자의 Request가 Platform Thread가 아니라 Virtual Thread로 매핑된다는 것이다. (아래 그림 참조)

파란색의 아래쪽 방향의 화살표는 Virtual Thread를 나타낸다. 지금은 Virtual Thread를 이용하므로 풀링(Pooling)으로 인한 제약이 없으며 따라서, 동접자 수 5000명이 있다면 이제 5000개의 Virtual Thread에서 병렬로 처리한다. 어플리케이션은 오직 CPU 연산을 수행할 때에만 Platform Thread(Carrier Thread)를 이용하게 된다. IO를 처리하는 동안에는 Carrier Thread가 다른 사용자들이 사용할 수 있도록 반환처리 된다. 이 아키텍처는 대량의 Virtual Thread를 지원하더라도 매우 적은 수(대략 코어 수만큼)의 Platform Thread만 요구된다.
이는 매우 중요한 것으로 어플리케이션의 확장성을 드라마틱하게 높여 준다. 왜나하면 개별 인스턴스가 훨씬 많은 수의 사용자를 지원할 수 있으며 이는, 동일한 수의 사용자를 지원하더라도 적은 수의 어플리케이션 인스턴스로 처리 가능하기 때문이다.
여기서 주목할 주요 포인트는 다량의 Virtual Thread를 사용할 경우, 다른 곳에서 리소스 제약 상황을 마주할 수 있다는 것이다. 예를 들면, 늘어난 데이터베이스 접속을 처리하기 위해 데이터베이스 Connection Pool을 늘려야 할 수 있으며, 더 많은 Socket Connection 지원을 위해 리눅스 시스템의 디폴트 설정을 변경해야 할 수도 있다.
요약
요약하자면, Virtual Thread는 Java Thread의 경량화된 구현체이며 File IO, Socket IO, Locking과 같이 IO 동작을 수행하는 동안에는 Carrier Thread가 반환처리 되도록 한다. IO 동작이 집약적인 엔터프라이즈 어플리케이션에 적합하며 대부분의 데이터베이스 어플리케이션에도 적합하다. 이는 적절한 시점에 Carrier Thread가 반환되도록 함으로써 이와 같은 IO 집약적인 어플리케이션의 확장성을 극대화 시켜준다. 대부분의 어플리케이션의 경우 Virtual Thread를 적용함으로써 성능이 훨씬 개선되는 것을 확인할 수 있을 것이다.
궁극적으로 이 기술이 프로젝트에 어떤 도움을 주는가?
대량의 고객을 처리하는 프로젝트는 훨씬 적은 수의 인스턴스와 리소스로 사용자를 지원할 수 있으며, 이는 프로젝트에 드는 비용을 획기적으로 줄여 줄 수 있다.