Transformer
참고: The illustrated Transformer
GPT는 Generative Pre-trained Transformer의 약자라고 알고 있다. 여기서 가장 중요한 역할을 하는 것이 Transformer일 것이다. 그렇다면 Transformer가 어떤 기능을 하기에 가장 중요한지 궁금증을 가지지 않을 수 없다. 논문의 포함해서 여러 자료를 살펴봐도 글자만 보이지 문맥이 보이지 않았는데 이 문서를 보고서 무릅을 탁 치게 되었다. 우선 쉬운 설명을 통해 궁금증을 해결하도록 해 준 Jay Alammar에게 감사를 드리고 나의 언어로 다시 정리해 보고자 한다.
나중에 자세하게 설명하겠지만 Transformer는 내부적으로 Attention이라는 개념을 사용한다. 이를 사용함으로써 그동안 문제로 지적됐던 느린 처리 속도를 획기적으로 개선하는 계기가 되었다. 빠른 속도의 기술적 배경에는 병렬처리가 있는데 Google Neural Machine Translation Model보다 성능을 능가하며 Google Cloud에서도 Transformer를 기본 모델로 사용하도록 추천하고 있다.
Transformer는 구글에서 발표한 논문 ” Attention is All You Need“에서 처음 소개 되었고 요즘, 이를 구현한 구현체(Tensor2Tensor, PyTorch를 활용한 구현 등)를 쉽게 찾아 볼 수 있다.
그럼 지금부터 Transformer의 개념을 이해하기 쉽도록 베일을 하나씩 벗겨보도록 하겠다.
A High-Level Look
Transformer를 몇 개의 박스로 심플하게 그려보면 아래와 같다. 예를 들어 프랑스어를 영어로 번역해 주는 번역 프로그램을 생각해 볼 수 있다.
중간 박스 Optimus Prime(Transformer ^^)의 뚜껑을 열어보면 아래 그림처럼 인코딩과 디코딩 컴포넌트 그리고 이들사이의 연결로 구성된다.
위 그림에서 ENCODERS로 표현된 인코딩 컴포넌트 내부는 아래 그림처럼 여러 개의 Encoder를 스택으로 쌓아 올린 구조를 가진다.(아래 그림은 6개를 표현했으나 특별한 의미가 있는 것은 아니며 다르게 설정 가능하다) 디코딩 컴포넌트도 동일하게 Encoder와 같은 개수의 Decoder를 스택으로 쌓은 구조를 가진다.
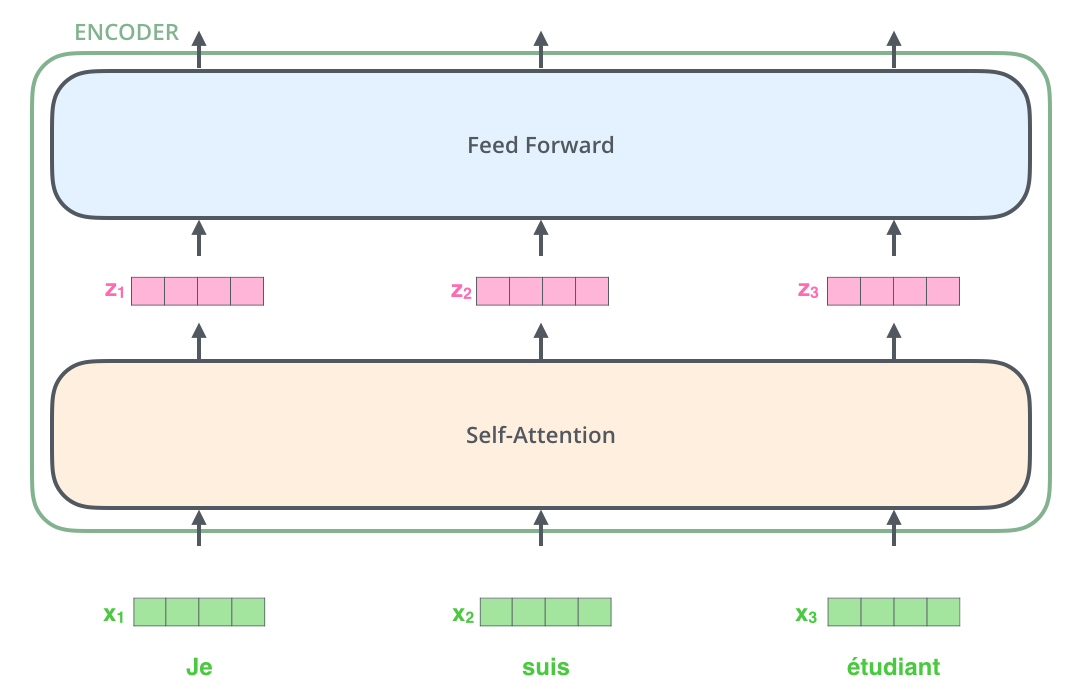
Encoder의 구조는 모두 동일하지만 Encoder들간에 적용되는 가중치(Weight)는 서로 다르다. 이들 각각의 Encoder는 내부적으로 아래와 같이 sub layer들로 구성된다.
Encoder에 입력되는 input값은 먼저 Self-Attention Layer를 통과한다. 이 Layer는 주어진 문장(sentence)의 특정 단어를 Encoding할 시점에 이 단어를 기준으로 다른 단어와의 관계가 어떤지를 파악하는 역할을 한다. (이후에 Self-Encoder에 대해 자세하게 알아볼 것임)
Self-Attention으로부터 출력되는 결과(Output)는 Feed Forward Neural Network의 입력(Input)값으로 들어간다. 정확히 각각 단어들에 독립적으로 동일한 Feed Forward Neural Network이 적용된다. Decoder도 이와 동일하게 2개의 Layer를 가진다. 그러나 두 Layer사이에 Attention Layer라는 것이 더 있으며 Decoding과정에서 Decoder가 입력으로 주어진 문장에서 연관성이 높은 단어에 Focusing하도록 도와준다.
Bringing The Tensors Into The Picture
Transformer의 주요 컴포넌트에 대해서 살펴봤다면 이제 입력값이 이들 컴포넌트 사이를 이동하면서 어떻게 출력값으로 변해가는지에 대해 알아 보자.

Embedding 과정은 Encoder 스택 중 가장 하단에 위치한 Encoder에서만 일어난다. 하지만 다른 Encoder들과 동일하게 적용되는 부분을 추상화 해보자면 512 크기의 Vector를 입력값으로 받는다는 것이다. 단지 차이가 있다면 가장 하단의 Encoder는 Embedding을 입력 값으로 받지만 그 윗단의 Encoder들은 바로 밑에 있는 Encoder의 출력을 입력값으로 받는다는 것이다. 이 Vector의 크기는 hyperparameter로 설정이 가능하며 일반적으로 Training Dataset 중에서 가장 긴 문장의 길이를 값으로 설정한다.
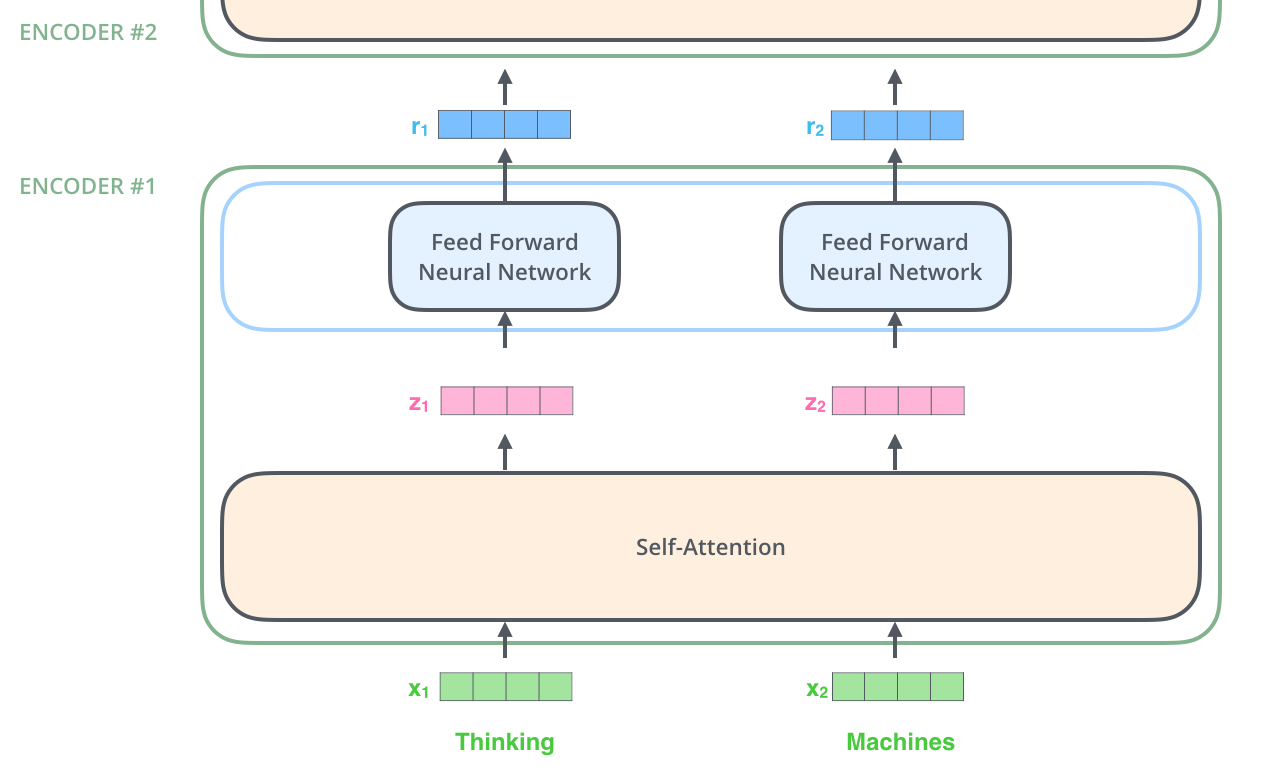
입력 문장을 Embedding하고 나면 이들 각각은 아래 그림과 같이 Encoder 내부의 두 개 Layer를 통과한다.
여기서 Transformer가 가진 속성 중 하나를 볼 수 있는데 각 위치별 단어는 개별적으로 Encoder를 통과한다는 것이다. Self-attention layer 내부에서 이들의 path는 서로 의존적이지만 Feed-forward layer에서는 서로간의 의존성이 존재하지 않는다. 따라서, Feed-forward layer를 통과할 때는 개별 path는 병렬로 실행 가능하다.
이제 짧은 문장을 예로 들어 Encoder의 내의 각각 sub Layer에서 어떤 일이 발생하는지 살펴 보자.
Now We’re Encoding!
앞에서 설명했듯이, Encoder는 Vector(Embedding)형태로 입력값을 받는다. 이 Vector는 Encoder 내부에서 self-attention layer를 통과 한 후 다시 feed-forward layer로 들어간다. 그런 다음 그 결과(Output)는 다음 단계 Encoder의 입력값으로 들어간다.
Self-Attention at a High Level
Self-Attention이라는 용어가 생경할 수 있다. 적어도 구글에서 “Attention is All You Need paper”라는 논문을 발표하기 전까지는 대부분 그 개념을 몰랐다. 그럼 이제 이것이 어떻게 동작하는지 알아보자.
다음 문장을 번역하려는 입력값이라고 해보자.
”
The animal didn't cross the street because it was too tired”
이 문장에서 ‘it”은 무엇을 가리키는가? it이 street를 가리키는가 아니면 animal을 가리키는가? 사람들에게는 단순해 보이는 질문이지만 알고리즘에게는 그렇지 않다.
“it”이라는 단어를 모델이 처리하고 나면 self-attention은 “it”이 “animal”과 가리키도록(관련성) 한다.
입력된 문장에서 모델이 특정 위치에 있는 단어를 하나씩 처리해 나갈 때 self attention은 단어 순서에서 다른 위치에 있는 단어들을 관찰함으로써 더 나은 인코딩을 위한 단서를 찾아낸다. Self-attention은 Transformer가 사용하는 방법으로 현재 처리중인 단어와 다른 단어들과의 연관성에 대한 “이해도(understanding)”를 현재 처리 중인 단어 녹여 넣는 방법이라 할 수 있다. (RNN에서 hidden state를 유지하는 것과 유사)
Self-Attention in Detail
Vector를 이용해서 self-attention을 어떻게 계산하는지 알아보자. 그 다음으로 이 매트릭스를 활용해서 실제 어떻게 구현되는지도 살펴보자
첫 번째 단계는 입력값으로 주어지는 각 단어별 Embedding으로부터 3개의 Vector를 만든다. 즉, 각 단어별로 Query Vector, Key Vector, Value Vector를 각각 도출한다. 이들 Vector는 Training을 통해 얻은 3개의 가중치(weight) 매트릭스를 Embedding과 각각 곱해서 구한다.
이렇게 생성된 Vector의 차원(dimension)은 Embedding Vector보다 낮다는 것에 주목하다. 생성된 Vector의 차원은 64이지만 Embedding과 입/출력 Vector들은 512 차원(dimension)을 가진다. 차원이 반드시 낮을 필요는 없으며 단지 multiheaded attention 연산이 일정하도록 하기 위해 아키텍처적으로 선택한 값이다.
그렇다면 “query”, “key”, “value” vector는 각각 무엇일까? attention 연산과 attention을 고려함에 있어 유용한 추상적인 개념이라 생각하면 된다. 예를 들어 설명하자면 key/value/query 개념은 정보 추출 시스템과 유사하다. Youtube에서 비디오를 검색할 때 검색엔진은 query(검색어)를 바탕으로 데이터베이스에 있는 관련 후보 비디오들의 key(비디오의 타이틀, 설명 등)을 매핑시킨다음 가장 잘 매칭되는 비디오들(values)를 결과로 보여준다. 아래의 설명을 보면 이들 값(vector)의 역할이 무엇인지 쉽게 이해할 수 있을 것이다.
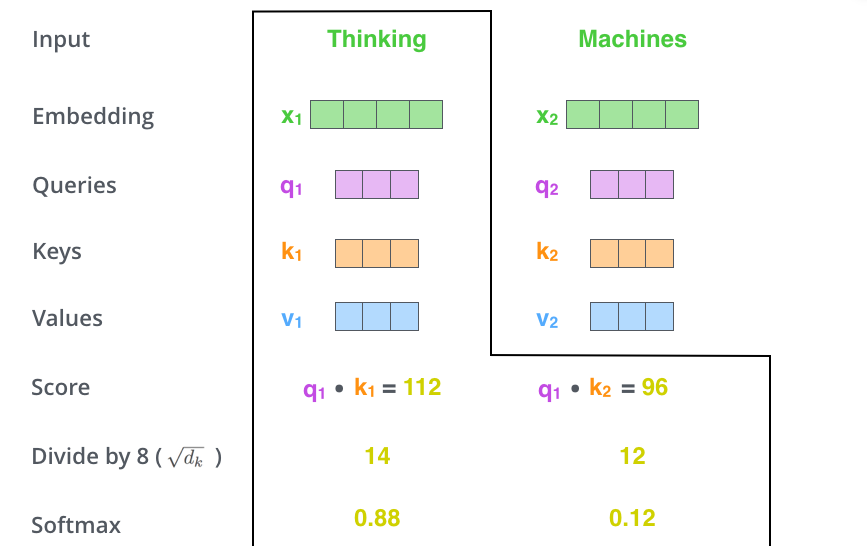
두 번째 단계는 score(attention score)를 계산하는 것이다. 예제에 있는 첫번째 단어(Thinking)에 대해 self-attention을 계산한다고 해보자. 이 단어(Thinking)을 기준으로 다른 단어들에 대한 attention score를 계산할 필요가 있다. 이 score는 입력 문장에서 특정 위치의 단어를 Encoding할 때 다른 단어들에 대해 어느 정도의 관심(focus)를 두어야 하는지를 결정한다.
이 score는 해당 단어의 query vector와 key vector를 dot product로 계산하며 #1위치에 있는 단어의 self-attention을 처리할 경우 score는 q1과 k1의 dot product가 될 것이고 두번째 score는 q1과 k2의 dot product가 된다.
세 번째와 네 번째 단계는 이렇게 계산된 score를 8로 나눈다.(key vector의 차원 -64- 의 제곱근. 이렇게 하면 더욱 안정적인 기울기를 만들어 낼 수 있다고 한다. 다른 값이 있을 수 있지만 default값이라고함) 그런 다음, 그 결과를 softmax 연산을하며, 이렇게 하면 score가 0 ~ 1 사이의 확률을 갖도록 normalize 된다.
Softmax score는 현재 단어를 기준으로 다른 단어들이 얼마나 많은 관심을 가지는지를 결정한다. 현재 위치의 단어가 가장 높은 softmax score를 가지는 것을 볼 수 있다. 그러나 떄로 현재 위치의 단어와 다른 단어가 어느정도 관련성이 있는지 확인하는데 유용할 수 있다.
다섯번째 단계는 value vector를 앞에서 계산한 softmax score와 곱한다. 이렇게 하는 이유는 관심을 두고있는 단어는 변경없이 유지되게 하도록 하고, 관련성이 적은 단어는 배제시키기 위해서이다.(예를 들면 아주 작은 값(0.001)을 곱하면 그 value는 아주 미미해 진다)
여섯번째 단계는 이렇게 곱해서 얻은 value vector를 모두 더한다. 이렇게 하면 현재 위치에 해당하는 단어에 대해 self-attention layer의 결과값을 얻게 된다.

이렇게 self-attention 계산이 종료되고, 결과 vector는 feed-forward neural network으로 전달된다. 실제 구현단계에서는 이 계산은 빠른 처리를 위해 matrix연산으로 이루어진다. 지금까지 단어 레벨에서 어떻게 연산 이루어지는지 개념적으로 봤으니 실제 어떻게 계산되는지 알아보자.
Matrix Calculation of Self-Attention
첫 번째 단계는 Query, Key, Value matrix를 계산하는 것이다. 먼저 embedding을 matrix X로 변환한 후 이 값을 가중치 matrix(weighted matrix – training고정에서 얻은 값)(WQ, WK, WV)와 곱셈한다.

마지막 단계로, matrix가 만들어 졌으므로 위 설명의 2번째부터 6번째 단계는 아래와 같이 하나의 식으로 간략하게 표현할 수 있다.

The Beast With Many Heads
구글에서 발표한 논문은 Self-attention layer에 multi-headed” attention이라는 개념을 추가해서 self-attention layer를 더 정교하게 만들었다. 이는 다음과 같이 2가지 측면에서 attention layer의 성능력 향상시켰다.
- 문장(sentence)에서 서로 다른 위치의 단어에 집중할 수 있도록 함으로써 모델 성능을 확장시켰다. 그렇다. 위 예제에서 z1은 다른 encoding의 값을 일부 포함하지만 자기 자신이 가장 큰 영향을 미친다. 예를 들어 “The animal didn’t across the street because it was to tired”라는 문장을 번역할 때 “it”이 가리키는 단어가 무엇인지 알 수 있다면 도움이 될 것이다.
- attention layer에서 다중의 “representation subspace”를 제공한다. 이후에 살펴 볼 것이지만 multi-headed attention을 통해 여러개의 Query/Key/Value 가중치 matrix(weighted matrices)를 가질 수 있다.(Transformer는 8개의 attention head를 가지며 따라서 8개의 각각 encoder/decoder를 가지게 된다.) 이들 Query/Key/Value 가중치들은 처음 random하게 initialize되며 training 된 이후 입력 embedding과의 projection 연산을 통해 각기 다른 representation subspace로 변환하기 위해 사용된다.
위에서 설명한 것처럼 여덟 번의 서로 다른 가중치 matrix와 self-attention 연산을 하면 아래와 같이 서로 다은 z matrix를 얻게 된다.
Feed-forward layer는 8개의 개별 matrix가 아니라 하나의 matrix를 입력으로 받으므로 하나의 matrix로 줄이는 방법이 필요하다. 어떻게 하면 될까? 8개의 matrix를 하나로 연결한 다음 추가적인 가중치 matrix WO와 곱하면 된다.
이것이 multi-head attention의 주요 내용이라 할 수 있다. 여려 개의 matrix를 볼 수 있는데 하나의 그림으로 시각화 하면 아래와 같다.
attention head에 대해 살펴 봤으니 이제 앞의 예제를 기반으로 문장에서 “it” 단어를 encoding할 때 attention head가 어디를 집중하는지 그림으로 살펴보자.
여기서 모든 attention head를 그림으로 표현해보면 해석하기 어려워 질 수 있다.
Representing The Order of The Sequence Using Positional Encoding
앞에서 설명한 모델에서 입력 문장에의 단어 순서를 설명하는 부분이 누락됐다. 이를 위해 Transformer는 각 input embedding에 어떤 vector를 더해 준다. 이 vector는 모델에서 학습한 특정 패턴을 따르며, 이는 각 단어의 위치와 문장 내에서 단어들간의 거리를 파악하는데 도움을 준다. 이렇게 하는 개념적 배경은 이 vector 를 embedding에 더해 주면 Q/K/V vector에 각각 투영(projection)되고 dot-product attention 과정에서 embedding vector들 간에 의미적인 거리(distance)를 제공해주기 때문이다.
embedding이 4차원으로 이루어졌다고 가정하면 실제 일어나는 positional encoding은 아래와 같다.
이 순서를 나타내는 vector는 어떤 형태를 띠고 있을까?
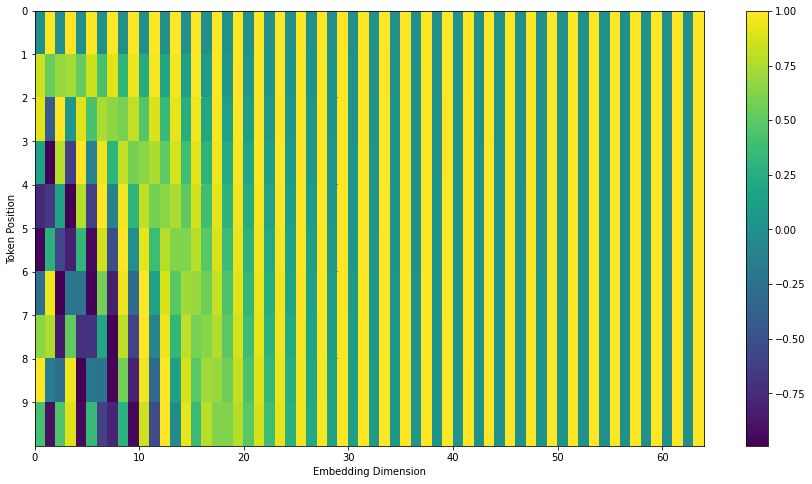
아래 그림에서 각 행은 vector의 positional encoding에 해당한다. 따라서, 첫번째 행은 입력된 문장에서 첫번째 단어에 해당하는 embedding과 덧셈한 positional encoding vector 이다. 각 행은 512개의 값을 표현하며 각 값은 1 ~ -1 사이의 값을 가진다. 각 값을 색으로 표현해보면 아래와 같은 패턴을 확인할 수 있다.
positional encoding 공식은 논문(section 3.5)에 설명되어 있다. get_timing_signal_1d() 에서 positional encoding을 생성하는 코드를 확인할 수 있다. 이는 유일한 positional encoding방법이 아니지만 보지 못했던 입력 sequence까지 볼 수 있도록 확장 가능하게 한다는 장점을 제공한다. (즉, training set의 문장 길이보다 더 긴 문장을 번역할 경우)
(저자 업데이트, 2020.7) 위에서 본 positional encoding은 Transformer의 Tensor2Tensor를 통해 얻은 것이다. Google 논문에서 사용한 method는 두 개의 signal을 직접 연결(concatenate)시킨 것이 아니라 서로 썩이게(interweave) 한 형태라는 점에서 약간 다르다. 다음 그림은 이렇게 할 경우 어떻게 시각화 되는지를 보여 준다.
The Residuals
다음으로 넘어가기 전에, Encoder 구조에서 상세하게 살펴봐야 할 점은 각 Encoder의 sub-layer(self-attention, ffnn) 사이에 남아있는 연결선(점선표현)이 있다는 것이다. 그 이후 단계로 layer-normalization가 따라온다.
vector와 self attention과 관련된 layer-normalize연산을 시각화 한다면 아래와 같이 보일 것이다.
이런 형태는 Decoder의 sub-layer에도 동일하게 적용된다. 2개의 encoder와 decoder가 stack으로 쌓인 Transformer를 생각해 본다면 다음과 같은 구조가 될 것이다.
The Decoder Side
이제 Encoder 부분에 해당하는 개념을 대부분 살펴 봤으므로 decoder에서 내부적으로 어떻게 동작하는지는 기본적으로 알 수 있지만 그래도, 전체적으로 어떻게 동작하는지 한번 살펴보자.
Encoder는 입력 문장을 프로세싱하면서 시작한다. 최상위에 있는 Encoder의 출력은 attention vector 셋(K, V)로 변형된다. 이들 vector는 “encoder-decoder attention” layer에 있는 각 decoder들에 의해 사용되며 “encoder-decoder attention” layer는 decoder가 input sequence(입력문장)에서 해당 단어와 correlation되는 곳에 focusing하도록 도움을 준다.
이후의 단계는 Transformer decoder가 출력을 종료한다는 것을 가리키는 특별한 기호를 만날 때까지 이 과정을 반복한다. 각 단계의 출력(output)은 다음 decoder 단계의 입력으로 들어간다. 그리고 decoder들은 encoder에서 했던 것처럼 자신의 결과를 상위로 bubble up 시킨다. 그리고, Encoder의 input을 대상으로 수행했던 것처럼 decoder input에 embedding을 먼저 수행하고 각 단어의 위치를 가리키리 위해 positional encoding을 더하는 과정을 수행한다.
Decoder에서 self attention layer는 encoder에서와는 약간 다르게 동작한다.
Decoder에서 self-attention layer는 output sequence에서 문장에서 앞쪽 영역으로만 처리하도록 허용돼 있다. 이는 self-attention과정의 softmax 이전 단계에서 future position( -inf 로 설정)을 masking함으로써 가능하다.
“Encoder-Decoder Attention” layer는 아래 단 layer에서 Query matrix를 만드는 과정을 제외하면 multiheaded self-attention과 비슷하게 동작하고 Key, Value matrix는 Encoder stack의 output에서 가져온다.
The Final Linear and Softmax Layer
Decoder stack은 float 형의 Vector를 출력한다. 이 값을 어떻게 단어로 변환할까? 이것이 마지막 단에 있는 Linear layer의 역할이다. 이 다음에는 Softmax Layer로 이어진다.
Linear Layer는 fully connected neural network이며 decoder stack에 의해 만들어진 vector데이터를 logit vector로 불리는 아주, 아주 큰 vector로 projection한다.
위에서 사용한 모델이 training dataset으로부터 학습하여 10,000개의 영어단어(모델의 출력 어휘)를 알고 있다고 가정하면 10,000개의 셀을 가진 logit vector가 만들어 진다. 이때 각 셀은 unique한 단어와 대응되는 점수(score)를 가지게 된다. 이것이 Linear layer의 거친 이후의 모델 결과(output)를 해석하는 방법이다.
Softmax layer는 이 점수(score)를 확률(probability)로 치환한다.(양수 값이며 0 ~ 1.0 사이의 값). 가장 높은 확률을 가진 셀이 선택되며 이와 연관된 단어가 현 단계에서의 결과로 만들어 진다.
Recap Of Training
지금까지 훈련된 Transformer를 통해 전반적인 forward-pass 과정을 알아봤으며, 모델을 training 하는 개념을 살펴보면 도움이 될 것이다.
training하는 동안 아직 학습안된 모델은 정확히 동일한 forward pass를 거치게 된다. 그러나, label된 training set으로 training하기 때문에 결과 값을(output)을 실제 정답과 비교할 수 있다.
이를 시각화 하기 위해 결과 어휘로 6개의 단어만 사용한다고 가정하자(“a”, “am”, “i”, “thanks”, “student”, “<eos>” (end of sentence))
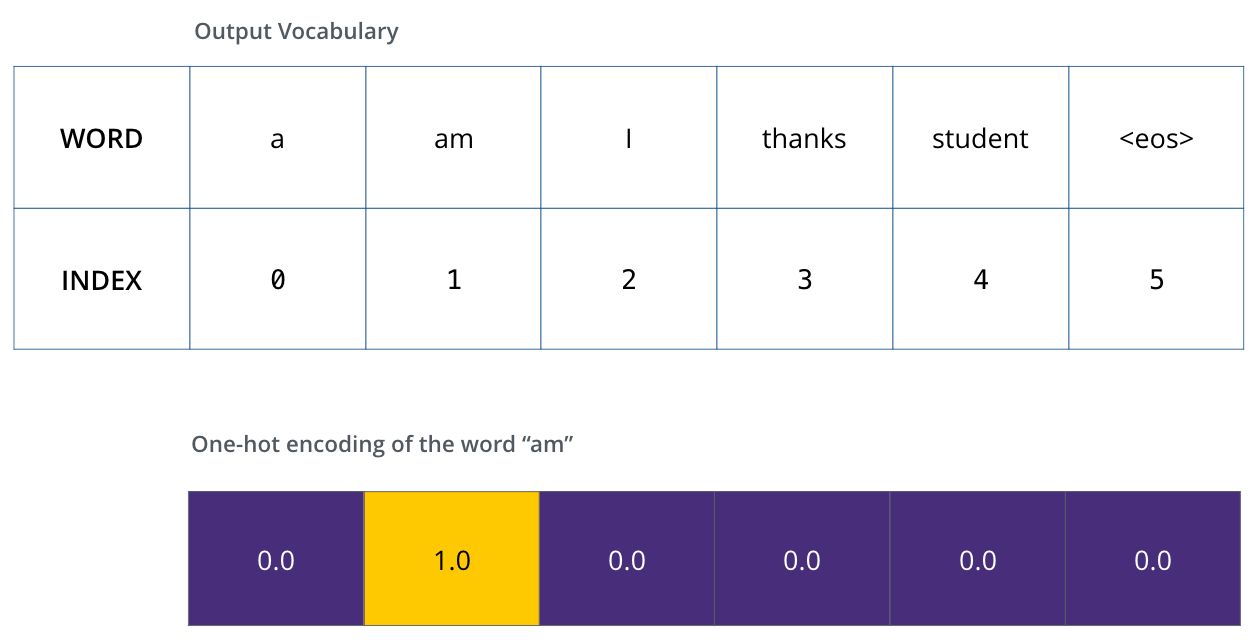
출력 어휘를 정의하면 각 단어를 지정하기 위해 동일한 크기의 vector를 사용할 수 있다. 이것을 on-hot encoding이라고 한다. 그래서 예를 들면, “am”단어를 아래의 vector와 같이 지정할 수 있다.
다음으로, 모델의 loss function에 대해 알아보자 – training단계에서 optimize하기 위해 사용하는 측정수단으로 매우 정확한 모델이 만들어지도록 하는 역할을 수행한다.
The Loss Function
모델을 training한다고 해보자. training과정에서 첫번째 단계로써 아주 간단한 예제(“merci”를 “thanks”로 번역)에 대해 training한다고 가정해보자.
이것이 의미하는 “thanks” 단어를 가리키는 확률값의 분포를 결과로 원한다는 것이다. 그러나 이 모델은 아직 train되지 않았으므로 아직 이런 결과가 발생되지 않을 것이다.
그렇다면 이 두개의 확률을 어떻게 비교할까? 여기서는 단순히 각 확률값을 뺄셈했다. 더 자세한 내용은 cross-entropy와 Kullback–Leibler divergence을 참고하기 바란다.
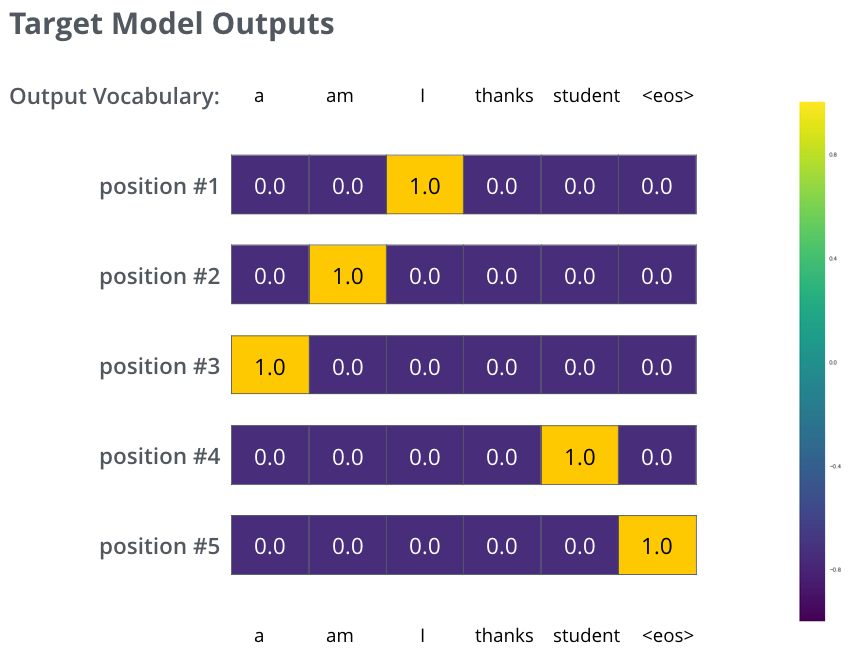
그러나 이것은 매우 단순화시킨 예제라는 것에 주목하자. 좀 더 현실적으로 “je suis étudiant”와 같이 한 단어보다 더 길 문장을 입력으로 사용할 것이며 출력은 “i am a student”가 될 것 이다. 이것이 의미하는 것은 모델이 연속적으로 확률의 분포를 출력한다는 것을 기대한다는 것이다. 여기서
- 각 확률의 분포는 vocab_size로 표현되는 vector의 크기(width)로 표현된다.(toy example에서 6을 사용하지만 현실적으로는 30,000 또는 50,000을 사용한다)
- 처음 확률의 분포는 “i”단어가 있는 셀에서의 확률이 가장 높다.
- 두번째 확률의 분포는 “am”단어가 있는 셀에서의 확률이 가장 높다.
- 이렇게 계속해서 다섯 번쨰로 출력되는 확률의 분포가 ‘<end of sentence>’기호를 가리킬 때까지 진행하며 이 또한 10,000개의 어휘 중에서 하나와 매핑된다.
충분히 큰 dataset으로 training한 후에 도출된 확률의 분포는 아래와 같을 것이라고 기대할 수 있다.
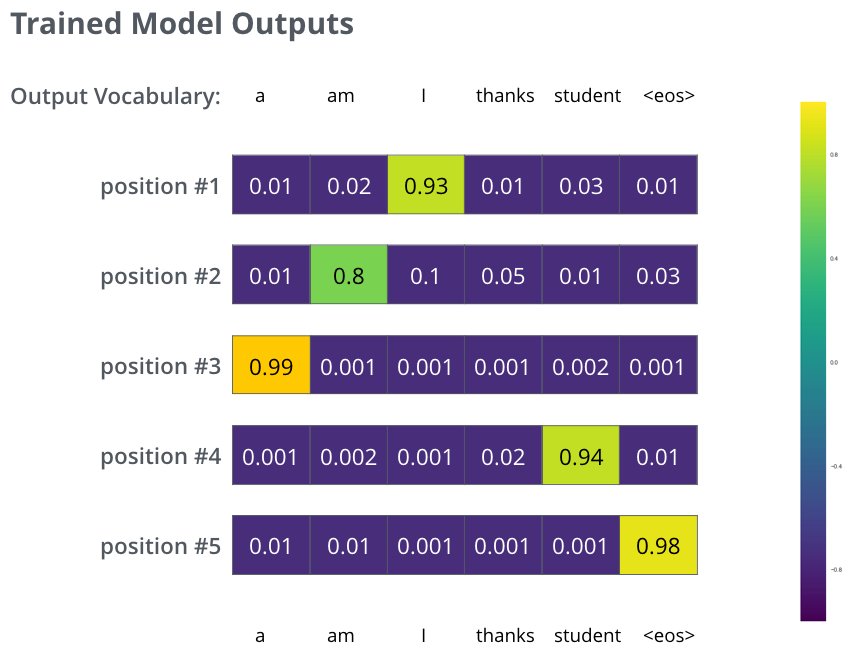
이제 모델이 한번에 하나씩 결과를 도출해 내기 때문에 모델이 확률의 분포 중에서 가장 높은 확률을 가지는 단어를 선택하고 나머지는 버리는 것이라고 가정할 수 있다. 이것이 동작 방법 중의 하나(greedy decoding)이며, 다른 방법은 최상위 2개의 단어(예: “I’, 와 “a”)를 취하고 다음 단계에서 모델을 두번 실행하는 것이다: 첫번째 출력이 단어 “I”라고 가정하고 다음 번의 첫번째 출력이 단어 “a”라고 가정하고 #1번쨰와 #2번째를 감안해서 오류가 적게 발생한 버전이 유지된다고 가정할 경우. 이 방법은 “bean search”라고 하며 예제에서 beam_size는 2이다(어떤 경우에라도 두 부분 가설(unfinished translation)은 메모리에 유지된다는 것을 의미한다), 그리고 top_beam 또한 2가 된다(2개의 translation을 반환한다는 것을 의미). 이들 2개 모두 실험해 볼 수 있는 hyperparameter이다.