알쓸코기: 알아두면 쓸데있는 코딩기술 – Deque
개발을 하다보면 어떤 자료구조를 사용하느냐에 따라 성능이 크게 달리지는 경우가 있다. 그리고 느린 성능으로 인해 사후에 원인을 분석하고 해결하려면 생각보다 많은 시간과 비용이 소모된다는 것은 대부분의 개발자들은 알고 있을 것이다. 이를 미연에 방지할 수 있는 가장 쉬운 방법은 개발 과정에서 어플리케이션의 성격과 구조를 충분히 이해하고 그 상황과 궁합이 가장 잘 맞는 자료구조를 선택하는 것이라 할 수 있다. 이런 생각까지 닿으면 명장의 목수가 연장을 자유자재로 다루듯 자료구조를 적절하게 선택, 적용하는 능력은 개발자들에게는 필수 요건이라 할 수 있다.
일반적으로 Java에서 List형태의 자료구조를 선택할 때 개발자들은 ArrayList를 많이 활용한다. ArrayList는 Read Operation을 index로 접근하므로 O(1)의 훌륭한 성능을 보여준다. 하지만 Element를 추가하거나 삭제할 때는 메모리 추가 확보라든가 배열 이동과 같은 내부적인 Operation으로 인해 비교적 높은 비용이 요구된다. 하지만 같은 List이면서 반대의 정점에 있는 자료구조가 LinkedList이다. LinkedList는 다들 아는 것처럼 Element간의 선/후관계를 Pointer를 이용하여 연결하므로 Element의 추가나 삭제가 Read Operation보다 저렴하고 효율적인 자료구조이다.
이와 같은 List 자료구조의 특성을 이해하면 아래와 같은 시나리오에서는 ArrayList보다 LinkedList를 선택하는 것이 더 높은 성능을 보장하는 개발이 될 수 있다.
길찾기 알고리즘으로 Dijkstra Algorithm이 많이 활용된다. 이 알고리즘은 출발지로부터 방문하는 각 노드까지의 최단거리 경로를 생성하므로 아래 그림과 같이 각 노드를 방문할 때 최단거리에 해당하는 바로 앞 노드의 Pointer를 Linked List 처럼 저장하는 형태로 구현할 수 있다(a, b, d). 알고리즘이 출발지(A)와 목적지(E) 사이에 최단경로를 찾았다면 목적지에서부터 역으로 출발지까지 되짚어 가면서 최종 경로(A-B-D-E)를 구성해야 한다.
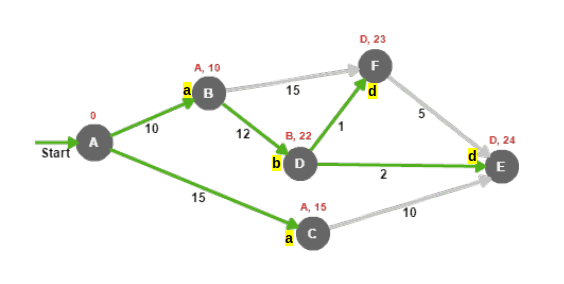
이때 ArrayList를 활용할 경우 최종 경로를 구성하는 방법은 아마도 아래의 코드와 같이 될 것이다. 참고로, Visit 클래스는 알고리즘이 노드를 방문할 때 각 노드까지의 최단거리 값을 유지하기 위한 Context 객체로 보면 된다.
class Visit {
private final Node node;
private Visit previous;
....
public List<Node> hops() {
List<Node> nodes = new ArrayList<>() {{ add(node); }};
for (Visit prev = previous; prev != null; prev = prev.previous) {
nodes.add(prev.node);
}
Collections.reverse(nodes);
return nodes;
}
....
}이 경우 hops()메소드는 목적지에서부터 역으로 출발지까지(E-D-B-A) 되짚어 가면서 각 방문지(Visit)의 노드정보를 List 형태(A-B-D-E)로 반환하는 기능을 수행한다. 반환되는 결과가 기대했던 값으로 확인이 되더라도 출발지와 목적지 사이에 Node의 개수가 상당히 많다면 성능을 고려하지 않을 수 없다. 여기서 활용한 ArrayList는 앞서 설명한 것처럼 Element를 추가(add)할 때 비용이 수반되는 자료구조이다. 또한 이후 코드에서 순서를 뒤짚(reverse)는 연산이 추가로 들어가므로 효율적이지 못하다. 따라서, 이런 이슈를 해결할 수 있는 자료구조를 선택한다면 성능측면에서 이득을 보게 될 것이다.
ArrayList대신 LinkedList 또는 ArrayDeque를 사용하면 이런 이슈를 해결할 수 있다. 하지만 여기서는 List형태로 결과를 반환하므로 LinkedList를 활용하여 hops() 메소드를 아래와 같이 변경하면 성능 향상을 꾀할 수 있다.
....
public List<Node> hops() {
LinkedList<Node> nodes = new LinkedList<>() {{ add(node); }};
for (Visit prev = previous; prev != null; prev = prev.previous) {
nodes.addFirst(prev.node);
}
return nodes;
}
....위 코드도 이전 코드와 같이 출발지를 만날 때까지 Visit을 역순으로 되짚어 가며 Visit의 노드를 List에 추가하는 로직을 보여준다. 하지만 여기서는 List의 마지막 부분에 add()하는 것이 아니라 addFirst()메소드로 List의 맨 앞부분에 추가해 나가는 방식이다. 이렇게 하면 자연스럽게 역순의 최종 리스트를 얻을 수 있는 구조가 된다. 또한 LinkedList의 특성상 맨 앞에 추가해 나가더라도 성능의 저하는 발생하지 않는다. 따라서 ArrayList로 접근할 경우 비효율적이었던 부분들을 한번에 모두 해결하는 셈이 된다.
참고로, LinkedList는 내부적으로 Pointer를 이용하여 앞/뒤 연결을 유지해야 하므로 ArrayList보다 메모리 사용량이 약간 늘긴 하지만 Element 추가와 순차접근(sequential access)에서 빠른 성능이 필요한 경우라면 Deque형태의 자료구조가 더 효율적이라 할 수 있다.