ChatGPT가 하는 것이 무엇이고… 왜 동작하는 걸까?
2022년11월 ChatGPT를 처음 접하던 날 내가 받은 인상을 아직도 생생하게 기억한다. 프롬프트 뒤에는 사람이 직접 입력을 하고 있다는 우스게 소리도 있었다. 내가 질문한 답을 기-승-전-결에 맞추어 군더더기 없이 깔끔하게 설명을 해주다니… 그것도 오류없이.
이게 가능하단 말인가! 더구나 프로그래밍 관련 질문에 Boilerplate Code를 곁들인 답을 뱉어 내는 것을 보며서 이제 정말 개발자의 종말을 보게 될 것인가란 약간의 두려움도 있었지만 ChatGPT가 내부에서 어떤 과정을 거치기에 이런 놀라운 결과를 만들어내는지 궁금해 지지 않을 수가 없었다.
GPT 이전의 AI는 주로 수학적인 설명을 토대로 미래를 추론하는 것이 대부분이었다면 ChatCPT는 기존에 없었던 내용을 새롭게 창작한다는 점에서 근본적 이해부터 다르게 접근하는 것이 맞을 것이란 생각이 들었다. 관련 자료를 찾아 봤지만 나의 짧은 기반 지식으로는 이해하기 어려웠다. 그러던 중 “What Is ChatGPT Doing … and Why Does It Work?“이란 글을 보고 고개를 끄덕이게 됐다. 나중에라도 다시 참고할 수 있도록 이해한 내용을 우리말로 풀어보고자 한다.
단지 한번에 한 단어씩 추가해 나가는 것이다.
ChatGPT의 결과물을 보면 사람이 작성한 것처럼 그 품질에 놀라움을 감출 수 없다. 어떻게 동작하길래 이게 가능할까? 이 문서의 목적은 ChatGPT 내부에서 어떻게 동작하는지 개괄적인 내용을 설명하는 것이다. 그런다음 어떻게 해서 사람들이 보기에 그럴듯하면서 의미있는 문장을 잘 만들어 내는지 알아보고자 한다.
먼저 설명해야 할 것으로는 ChatGPT의 기본 동작 방식은 현재까지 입력받은 문장을 근간으로 해서 이후 그럴듯한 연결문(reasonable continuation)을 만들어 낸다는 것이다. 여기서 그럴듯한(reasonable)은 어떤 사람이 웹상에 작성된 수십 억개의 문장을 보고난 후 작성할 법한 것을 말한다.
자 그럼, “The best thing about AI is its ability to“라는 문장이 있다고 하자. 웹 상에서 사람들이 작성한 수십억 페이지를 스캔한 다음 이와 동일한 문장을 모두 찾아내고 그 다음으로 어떤 단어가 얼마나 자주 나타나는지 확인해 본다고 하자. 단순 문자 단위로만 보는 것이 아니라 의미적으로 부합하는 단어를 찾아낸다는 것을 제외할 경우 ChatGPT는 이런 형태의 작업을 매우 효율적으로 수행한다. 그러나 최종 결과로 아래와 같이 다음에 이어질 단어의 확률 순위 리스트를 생성해 낸다.

눈에 띄는 점으로는 ChatGPT가 소설을 쓰는 것처럼 동작할 때 실제 내부적으로는 현재까지 주어진 문장을 기반으로 다음에 어떤 단어가 나올까? 라는 질문을 반복해서 계속 수행한다는 것이다. 이러면서 단어를 추가해 나간다. (좀 더 정확하게 표현하자면 token을 추가해 나가는 것이다. token은 어간 어미처럼 한 단어에서 일부분이 될 수 있으며 이를 활용하여 가끔은 새로운 단어를 만들어내기도 한다.)
각 단계에서 단어별 나타날 빈도의 확률을 생성하는데 그렇다면 어떤 확률의 단어를 다음에 작성할 단어로 선택할까? 아마도 가장 높은 확률의 단어를 선택할 것으로 생각할 수 있다. 하지만 이 확률이 마법적인 현상을 만들어 낸다. 어떤 이유에서 만약 가장 높은 확률의 단어를 항상 선택하게 된다면 아마도 아주 평이한 문장들이 만들어 질 것이다. (어떤 경우에는 동일한 내용이 반복될 수도 있다.) 그러나 가끔식 상대적으로 낮은 확률의 단어를 선택해 주면 좀 더 재미있는 문장을 결과로 얻을 수 있을 것이다.
여기서 무작위(randomness)가 있다는 것은 동일한 프롬프트를 여러 번 사용하더라도 매번 다른 형태의 결과가 만들어진다는 것을 의미한다. 이런 마법적인 현상을 유지하기 위해 “temperature”라 특별한 파라미터가 사용한다. 이를 이용하여 어떤 빈도로 확률이 낮은 단어를 사용할지 결정하며 문장을 생성할 때 0.8이 가장 적절한 temperature 값으로 간주된다. (이론이 있는 것이 아니라 사용해보니 이 값이 가장 적절하더라는…)
이 글에서 사용하는 예제는 일반 PC에서도 동작하는 ChatGPT 2 모델을 이용하며 Wolfram Language 를 사용해여 설명한다. 굳이 이 언어를 알아 둘 필요는 없다.
예를 들어 앞에서 설명했던 단어별 확률 테이블을 어떻게 만드는지 보여준다. 먼저, 아래와 같이 내부적으로 사용하는 언어모델을 지정한다.
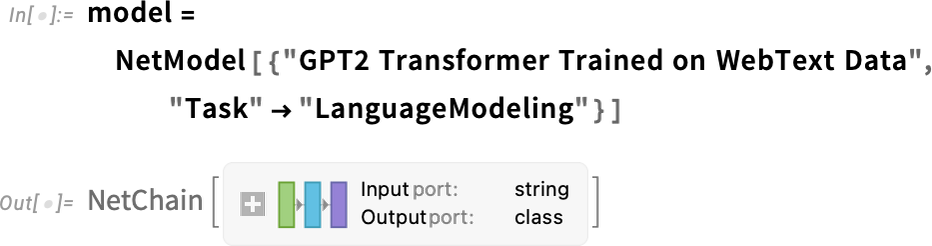
나중에 좀 더 자세하게 설명할 것이지만 우선은 이 모델을 블랙박스로 두고 확률이 높은 5개의 단어를 질의하면 아래와 같은 결과가 나온다.

아래는 이 결과를 바탕으로 포맷을 갖춘 “dataset”로 바꾼 결과이다.

다음은 반복해서 이 모델을 적용하면 어떤 결과가 나오는지 보여준다. 각 단계에서 확률이 높은 단어를 선택하여 추가한다.

더 길에 이어간다면 어떤 결과가 만들어질까? 이 경우와 같이 “zero temperature”를 사용할 경우 계속 이어지는 문장은 오히려 혼란스럽고 반복되기도 한다.

그러나 가장 높은 확률의 단어를 항상 선택하는 것이 아니라 최상위 확률이 아닌 단어를 랜덤하게 선택하면(여기서 random은 temperature 0.8에 해당) 어떨게 될까? 다시 문장을 만들어 보면

매번 시도할 때마다 서로 다른 temperature 값이 random하게 선택되며 아래의 예제처럼 생성되는 문장도 다르게 생성된다.

이 예제에서 보듯이 확률은 가파르게 떨어지긴 하지만 첫번쨰로 이어지는 단어에도 선택할 수 있는 단어의 종류가 많다.

이제 문장을 길게 어어가면 어떻게 될까? 아래에 Random 예제에서 보듯이 그 결과가 0-temperature보다 좋아보인다. 하지만 여전히 부자연스런 부분이 일부 존재한다.

이 결과는 가장 단순한 GPT-2 모델(2019)을 사용하여 만들어 졌다. GPT-3모델을 이용하면 위의 결과보다 더 나은 결과를 만들어 낼 것이다. 아래는 동일한 프롬프트로 GPT-3모델을 이용하여 0 temperature로 생성한 문장이다.

다음은 temperature 0.8로 Random하게 생성한 예제이다.

그렇다면 대체 이 확률은 어디서 오는걸까?
ChatGPT는 항상 확률에 기반하여 다음에 오는 단어를 선택한다고 했는데 그럼 이 확률은 데체 어디서 오는 것일까? 영어 단어가 아니라 한번에 알파벳 하나씩 생성하는 간단한 예를 생각해보자. 각 문자마다 확률이 어떻게 되는지 알아 낼 수 있을까?
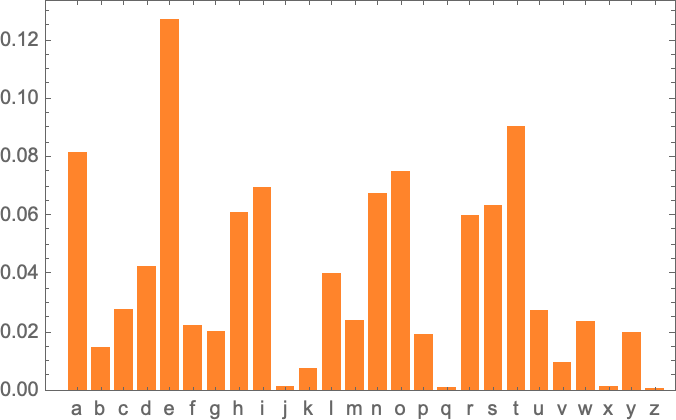
가장 간단하게 해볼 수 있는 것으로 영어 단어를 하나 선택한 후 알파벳 문자가 나타나는 빈도수를 계산해 보는 것이다. 그럼 예를 들어 다음은 “cat”을 설명하는 위키피디아 페이지에서 각 문자 빈도 수를 계산한 것이다.

그리고 아래는 동일하게 “dog”에 대한 각 문자 빈도 수 이다.

결과는 비슷하지만 동일하지는 않다. (당연히 o는 dog 단어 포함되어 있으므로 dog 문서에서 빈도수가 더 많다) 나아가 충분히 많은 샘플들에 대해 적용해 보면 적어도 아래와 같이 일관된 결과를 얻을 수 있다.

위의 확률 분포로 일정 길이의 문자열을 생성하면 아래와 같다.

사이사이에 특정 확률의 공백 문자 넣어 단어형태로 자르면 다음과 같다.

그리고 단어의 길이를 실제 단어의 길이처럼 만들면 좀 더 그럴듯한 단어가 만들어 진다.

아직 실제 단어를 만들어 내진 못했지만 보기에 더 개선된 것처럼 보인다. 더 진행해 보려면 그냥 Random으로 글자를 선택하는 것 이상을 해볼 필요가 있다. 예를 들면 “q”글자가 있다면 다음으로 올 글자는 “u”가 될 가능성이 높다는 것을 안다.
아래는 각 글자별 나타나는 확률을 보여준다.
다음은 두 글자 조합(2-grams)을 했을 때의 확률을 보여 준다. 첫 번째 글자는 가로축이며 두 번째 글자는 세로축으로 표현했다.

이렇게 해서 보면 “q”컬럼은 “u”행을 제외하고는 공백(확률 0)이라는 것을 알 수 있다. 자 이제 단어를 생성할 때 한 글자씩 생성하는 것이 아니라 위 그림에 있는 2-gram 확률을 이용하여 한번에 두 글자씩 보면서 생성해 보자. 다음은 간단하게 생성한 결과를 보여준다. 보면 알겠지만 몇몇은 실제 단어를 포함하고 있다.

충분히 많은 문장으로 적용해 보면 한글자 또는 두 글자 확률을 이용할 때 보다 긴 문자열에 대해 더 나은 예측치를 만들어 낼 수 있다. 길이가 더 긴 n-gram의 확률을 적용하여 임의로 단어를 생성해 보면 훨씬 더 현실적인 단어가 만들어 지는 것을 볼 수 있다.

이제 글자 단위가 아니라 단어 단위로 처리한다고 가정해 보자. 영어에서 주로 사용하는 단어는 대략 40,000 단어 정도 된다. 영어로 된 수 백만 권의 거대한 말뭉치(Corpus)를 살펴보면 각 단어별로 얼마나 자주 사용되는지 추정해 낼 수 있다. 이 추정치를 활용하면 문장을 만들어 낼 수 있다. 이때 문장에서의 각 단어는 말뭉치로부터 도출한 확률에 기반하여 각각 임의(random) 선택되었다. 아래는 이렇게 도출된 샘플을 보여준다.

당연한 얘기지만 이 문장은 어떤 의미를 갖지 않는다. 그렇다면 어떤 방법으로 개선시킬 수 있을까? 앞에서 문자 단위로 했던 것처럼 각 단어별 확률을 고려하는 것이 아니라 한 쌍의 단어 또는 이 보다 더 긴 n-gram 의 단어별로 확률을 먼저 고려해 볼 수 있다. 이어지는 한 쌍의 단어를 대상으로 적용 해보면 아래와 같이 5개의 예제를 만들어 낼 수 있다. 모든 문장은 “cat”이라는 단어로 시작한다.

이제 더욱 더 그럴듯한 문장으로 보인다. 이제 이렇게 생각해 볼 수 있을 것이다. 충분히 긴 n-gram을 사용할 수 있다면 초기 단계의 ChatGPT를 만들어 낼 수 있지 않을까? 어떤 면에서 보면 에세이(글)에 대한 정확한 확률을 활용하면 에세이 길이에 해당하는 단어 순서(sequence)를 만들어 내는 ChatGPT를 만들 수 있을 것이다. 하지만 여기에는 문제가 있다. 이런 확률을 만들어 내기 위해 필요한 충분히 많은 양의 영어 문서가 없다는 것이다.
웹을 Crawling하면 수 천억 개의 단어를 얻을 수 있다. 전차 출판된 책에서는 또 다른 수 천억 개의 단어를 얻을 수 있다. 그러나 일반적으로 많이 사용하는 40,000개의 단어를 활용할 경우 2-gram으로 생성 가능한 갯수는 이미 16억개에 달한다. 그리고 3-gram으로 가능한 갯수는 60조 개나 된다. 따라서 이렇게 수집한 문장에서 이런 단어 개수별에 따른 확률을 추정하기란 거의 불가능하다. 20개 단어로 구성된 짧은 글을 생성할 때까지 가능한 수는 우주에 있는 분자의 개수보다 크다. 따라서 이렇게 가능한 조합을 모두 만들어 낸다는 것은 불가능하다고 보면 된다.
그렇다면 무엇으로 할 수 있을까? 어떤 모델을 먼저 만들고 이를 이용하여 확률을 유추해 내는 것을 생각해 볼 수 있다. 이 확률로 단어의 순서가 만들어 진다. 이 순서는 거대한 말뭉치에서 명시적으로 보지 못했던 순서일 수도 있다. 그리고, ChatGPT의 핵심에는 정확히 Large Language Model(LLM)이 있으며 이는 뛰어난 능력으로 확률을 추정해내도록 만들어 졌다.
모델이 무엇일까?
피사의 탑 각 층에서 공을 떨어뜨리면 바닥에 닿을 때까지 시간이 얼마만큼 걸릴지 알고 싶다고 하자. 각각의 케이스별로 테스트를 한 다음 그 결과를 테이블로 정리한 후 활용하거나, 계산을 통해 결과를 도출하도록 이론과학의 핵심 델을 만드는 것이다.
각 층에서 공을 떨어뜨리면 얼마 만큼의 시간이 소요되는지 이에 대한 데이터를 가지고 있다고 하자.

만약 데이터에는 없는 층에서 공을 떨어뜨릴 경우 시간이 얼마만큼 소요되는지 어떻게 알아 낼 수 있을까? 이와 같은 특별한 경우는 알려진 물리법칙을 적용하면 된다. 하지만 주어진 것은 데이터 뿐이고 적용 가능한 법칙을 모르는 상태라고 가정할 경우 아래 그림처럼 직선을 긋는 것으로 모델을 만들어 수학적 추론을 할 수 있다.

다른 형태의 직선을 그을 수 있지만 이 선이 평균적으로 봤을 때 주어진 데이터에 가장 근접하는 선이다. 이 직선을 활용하면 어떤 층에서 공을 떨어뜨리더라도 소요시간을 예측해 낼 수 있다.
문제 해결에 직선을 이용하면 된다는 것을 어떻게 생각해 냈을까? 어떤 단계에서는 그렇게 하지 않았다. 단지 수학적으로 심플하며 측정한 값들의 양이 많을수록 수학적으로 단순한 것에 잘 맞아 들어간다는 사실에 익숙해 졌기 때문이다. 수학적으로 a + b x + c x2 와 같이 더 복잡한 식으로 시도해 볼 수 있다. 이 경우 더 좋은 결과를 얻을 수 있다.

또는 매우 잘못될 수도 있다. 여기서는 a + b/x + c sin(x) 식을 사용했다.

모델이 없는 모델”은 결코 없다는 것을 이해하는 것이 중요하다. 적용하려는 어떤한 모델도 특별한 내부 구조와, 데이터에 맞추도록 설정 가능한 파라미터들을 가진다. ChatGPT의 경우 많은 양의 파라미터가 사용되며 실제 1,750억개나 된다.
그러나 놀라운 일은 ChatGPT의 내부 구조가 그럴듯하게 보이는 문장 길이(essay-length)도 생성해 낼만큼 다음에 올 단어의 확률을 잘 계산해내는 모델도 충분히 만들 수 있다는 것이다.
사람과 유사한 일을 하는 모델
앞에서 활용한 예제들은 근본적으로는 단순 물리학을 활용해 수치 데이터를 위한 모델 생성을 보여준다. 여기서 언급한 물리학은 단순 수학이 적용되는 것으로 몇 백년에 걸쳐 알고 있는 내용이다. 그러나 ChatGPT는 인간이 언어로 사용하며 사람의 두뇌에서 생성되는 문자에 대해 모델을 만들어야 한다. Simple한 수학과는 달리 아닌 아직 발견하지 못한 그런 모델을 말한다. 그럼 이런 모델이란 어떤 것일까?
언어를 언급하기에 앞서 이미지 인식과 같이 인간과 유사한 또다른 형태의 작업에 대해 얘기해 보자. 이런 유형의 단순한 예제로 숫자가 새겨진 이미지를 생각해 보자.

먼저 할 수 있는 것은 각 숫자에 대하 다양한 샘플 이미지를 확보하는 것이다.

주어진 이미지가 특정 숫자에 해당한다는 것을 알아내기 위해 기존에 확보한 이미지와 명시적으로 pixel-by-pixel 대조해 볼 수 있다. 그러나 인간은 확실히 이런 일을 훨씬 잘 수행한다. 왜냐하면 손으로 쓴 숫자든 다양한 형태로 변형된 숫자든 인간은 그 숫자를 인식할 수 있기 때문이다.

위에서 수치 데이터에 대한 모델을 만들었을 때 입력 값 x을 받은 다음 어떤 a와 b값을 이용하여 단순 a + b x 연산을 수행했다. 그렇다면 여기서 검은색의 pixel을 xi 값이라 보면 이런 변수를 실행했을 때 해당 이미지가 어떤 숫자를 나타내는지 답을 주는 어떤 function을 만들 수 있을까? 이런 function이 가능하다는 것이 확인됐다. 하지만 이는 당연하게도 그렇게 단순하지 않다. 전형적인 예제만 보더라도 5,000만번 이상의 수학적 연산을 필요로 한다.
이미지의 모든 pixel을 배열 형태로 function 입력 값으로 제공하면 그 이미지가 어떤 숫자를 가리키는지를 반환하는 것이 최종 형태가 될일 것이다. 나중에 이런 function이 어떻게 만들어 지고 신경망(neural net)에 대해서도 설명하겠지만 우선 지금은 이 function을 블랙박스로 두자. 이 function은 손으로 작성한 숫자 이미지를 입력(pixel값을 표현하는 배열)받고 이 이미지가 나타내는 숫자를 반환한다고 하자.

그러나, 여기서 실제 어떤일이 발생되는 걸까? 아래 그림과 같이 점진적으로 숫자를 blur처리한다고 해 보자. function이 처음 일부는 “2”로 인식하겠지만 곧 숫자를 인식하지 못하고 엉뚱한 결과를 반환하기 시작한다.

하지만 우리는 잘못된 결과라고 어떻게 말할 수 있는 걸까? 이 경우는 우리가 숫자 “2”의 이미지를 blur처리했다고 사전에 인지하고 있다. 그러나 우리의 목표가 사람이 이미지 인식을 하는 것과 같이 모델을 만드는 것이라면 진짜 해야할 물음은 이미지가 어디서 왔는지 모른 상태에서 위와 같이 blur된 이미지를 보았을 때 사람이 행하는 것이 무엇인지에 대한 질문일 것이다.
우리가 만든 function으로 부터의 결과가 사람들이 말하는 것과 일치한다면 우리는 “good model”가졌다고 할 수 다. 그리고 명확한 과학적 사실은, 이미지 인식 작업과 관련하여 이제는 어떻게 이런 function을 구축하는지 근본적으로 알고 있다는 것이다.
이것이 제대로 동작하는지 수학적으로 검증할 수 있을까? 그렇지 못하다 왜냐하면 이렇게 하기 위해서는 인간이 무엇을 하는지에 대한 수학적 이론을 가지고 있어야 하기 때문이다. 숫자 “2” 이미지에서 pixel 몇 개를 변경해보자. 우리는 이미지에서 pixel 몇 개를 변경하더라도 여전히 숫자 “2”이미지라고 생각한다. 그러나 얼마만큼 이렇게 계속 할 수 있을까? 이는 인간의 시각적 인식에 관한 문제이다. 그리고 당연히 이에 대한 답은 벌이나 문어와는 다를 것이다.
신경망(Neural Nets)
이미지 인식과 같은 작업관련 모델은 실제 어떻게 동작하는 것일까? 현재 가장 잘 알려지고 성공적인 방법은 신경망(neural net)을 이용하는 것이다. 오늘날 사용되는 방법과 가장 유사한 방법으로 1940년대에 고안된 신경망은 두뇌의 동작원리를 간단하게 구현한 것으로 여겨진다.
사람의 두뇌에는 약 1,000억개의 신경세포인 뉴런이 존재한다. 각각의 뉴런은 1초에 1,000회 정도의 전기신호를 만들어 낼 수 있다. 뉴런은 복잡한 망(네트워크)로 연결되어 있고 각 뉴런은 나무처럼 가지를 가지고 있으며 1,000여개 정도의 다른 뉴런으로 전기신호를 전달한다. 대략적으로 말해 뉴런이 특정 순간에 전기신호를 발생시킬지 말지 여부는 서로 상이한 가중치(weights)로 연결된 다른 뉴런으로부터 어떤 신호를 받느냐에 따라 결정된다.
우리가 이미지를 볼 때 일어나는 현상은 이미지로 부터 나온 빛 광자(photon)가 우리 눈 뒤에 있는 망막(photoreceptor)세포에 도달하면 신경세포에 전기신호를 발생시킨다. 이들 신경세포는 다른 신경세포들과 연결되어 있고 결국 이 신호는 뉴런들로 형성된 일련의 레이어(layer)를 통과하게 된다. 그리고 이 과정에서 우리는 이미지를 인지하게 되며 궁극적으로 우리가 숫자 “2”를 본다라는 생각을 형성하게 된다. 그리고 마지막에는 아마도 “two”라는 단어를 소리내어에 말하기도 한다.
앞 단락에서 설명한 “black-box” function은 이런 신경망을 수학적으로 구현한 버전이라고 보면 된다. 여기서는 11개의 레이어를 갖는다. (“core layer”는 4개)

이런 신경망에서 특별히 이론적으로 파생된 것은 없으며 단지 1998년에 엔지니어링의 결과로 만들어지고 실제 동작한다고 알게된 것일 뿐이다. (물론, 이것은 우리 두뇌가 어떤 생물학적 진화를 거쳐 만들어졌는지에 대한 설명과도 크게 다르지 않다)
자, 그렇지만 어떻게 이와 같은 신경망이 사물을 인지하는 걸까? 그 핵심에는 attractor이라는 개념이 있다. 아래와 같이 “1”과 “2”를 손으로 작성한 이미지가 있다고 하자.

어떤 방법을 통해 모든 “1”을 한 곳으로 모으고 “2”를 다른 곳으로 모으고 싶다고 하자. 달리 표현해서 어떤 이미지가 “2”보다 “1”에 더 비슷하다면 “1”이라는 곳으로 모으고 역으로도 한다고 하자.
좀 직관적인 분석방법으로 평면(plane) 위에 점으로 표시한 어떤 장소들이 있다고 하자.(실제로는 커피숍의 위치가 될 수도 있다) 그런다음, 면 위의 어떤 곳에서 출발하여 항상 가장 근접한 점으로 이동하고 싶다고 하자(항상 가장 가까운 커피숍으로 이동한다고 가정). 이 면을 이상적인 분수령으로 분리된 영역(attractor basins)으로 나누어 표현할 수 있다.

이렇게 하는 것을 인지 과정을 구현하는 것이라고 생각할 수 있다. 이는 이미지에 쓰여진 숫자가 무엇과 가장 닯았는지 알아내는 것이 아니라 직관적이로 특정 포인트가 어떤 점과 가장 가까운지 알아 보는 것이라 할 수 있다. (여기서 보여주는 Voronoi 다이어그램은 2D 유클리드 공간에서 점들을 분리시킨다. 숫자 인지가 이와 매우 유사한 과장이라 생각할 수 있다. 그러나 각 이미지에서 검은색 pixel로 만들어진 784-dimensional(28*28) 공간이란 점에서 차이가 있다)
그렇다면 어떻게 신경망이 인지 작업을 수행하도록 만들 수 있을까? 아래와 같은 아주 단순한 케이스를 생각해 보자.

우리 목표는 위치를 나타내는 {x,y} 값을 입력 받아 이 세개의 점 중에서 가장 가까운 점을 알아내는 것이다. 다르게 말하면 아래처럼 신경망이 {x,y}의 function을 연산하도록 하는 것이다.

그렇다면 신경망으로 어떻게 이것을 할 수 있을까? 궁극적으로 신경망은 neuron이 서로 연결된 집합체(connected collection)이다. 일반적으로 층(Layer) 형태로 정렬되어 있으며 아래와 같은 간단한 예제로 표현할 수 있다.

각각의 뉴런은 간단한 수치 계산을 위한 function으로 설정되어 있으며 신경망을 동작시키기 위해 상단에서 x, y좌표를 입력값으로 전달한다. 그런다음, 각 Layer에 있는 뉴런들로 하여금 각자의 function을 실행하고 그 결과를 다시 망(network)을 통과시킨 후 궁극적으로 하단부에서 최종 결과를 산출해 낸다.

생물학적 배경으로 바탕으로 각각의 뉴런은 이전 Layer의 뉴런들로부터 incoming 연결을 가지며 이들 연결(connection)에 어떤 가중치(weight – 양수 또는 음수가 될 수 있음)를 할당받는다. 특정 뉴런의 값(value)은 이전 단계의 뉴런의 값과 이 뉴런과의 connection 할당된 가중치를 곱한 다음, 이렇게 이전 Layer와 연결된 connection들의 합계를 구하고, 이 합계와 어떤 상수를 더한다. 그런 다음 마지막으로 activation function을 적용한다. 수학의 관점에서 보면 뉴런이 x = {x1, x2 …} 입력을 가지면 f[w . x + b]을 계산하며 여기서 w 는 가중치(weights)이고, 상수 b는 각 뉴런별로 다른 값이 설정된다. 그리고 function f는 동일하게 적용된다.
w . x + b를 연산은 matrix의 곱셈과 덧셈만 수행하면 된다. activation function f 는 모델에 비선형적인 특성을 반영한다. 다양한 activation function을 일반적으로 적용며 여기서는 Ramp(or ReLU – Rectified Linear Unit)를 적용한다.

신경망이 수행하는 각 task마다 각기 다른 가중치(weight)를 적용한다. 나중에 설명하겠지만 이 가중치는 머신러닝을 활용하여 샘플데이터로부터 모델을 훈련시킨 결과로 얻어진다.
궁극적으로 모든 신경망은 플어쓰면 혼란스러워 보이겠지만 수학적인 function으로 최종 귀결된다. 위의 예제는 아래와 같은 식이 될 것이다.

ChatGPT의 신경망도 양이 엄청 많겠지만 이와 유사한 수학적 함수로 표현할 수 있다.
이제 각각의 개별 뉴런으로 돌아가보자. 아래 그림은 2개의 input을 갖는 뉴런이 다양한 가중치(weight)와 상수를 갖는(activation function으로 Ramep를 적용) function의 예를 보여준다.

위의 예제보다 더 큰 네트워크는 어떻게 될까? 아래 그림은 더 큰 네트워크가 연산하면 어떻게 보이는지를 나타낸다.

이 그림은 정확한 점이라기보다 위에서 봤던 근접한 점 function에 가깝다.
다른 신경망에서는 어떻게 되는지 한번 보자. 나중에 설명하겠지만 각 Case에서 가장 적절한 가중치를 찾기 위해 머신러닝을 사용한다. 다음 그림은 이렇게 찾은 가중치를 활용하여 신경망이 연산하는 것을 보여 준다.

일반적으로 네트워크가 클수록 function은 해결하려는 값을 더 정확하게 계산한다. 그리고 일반적으로 각 “attractor basin”의 중심부일수록 더 정확한 해답을 얻을 수 있다. 그러나 경계선(가장자리) 영역에서는 신경망이 결정하는데 어려움을 겪으며 그 결과가 혼란스러울 수 있다.
이와 같이 심플한 수학적 스타일의 “인식 작업(recognition task)”을 활용하면 정답이 무엇인지 명확하다. 그러나 손으로 작성된 숫자를 인식하는 문제의 경우 그리 명확하지 못하다. 숫자 “2”를 너무 이상하게 써서 “7” 또는 다른 숫자로 보인다면 어떨까? 신경망이 숫자를 어떻게 구분하는지 여전히 질문할 수 있으며 이는 어떤 실마리를 제공한다.

신경망이 이런 구분을 수학적으로 어떻게 하는지 말할 수 있을까? 어렵다. 그냥 신경망이 계산하는 것이다라고 말할 것이다. 그러나 이는 인간이 구분하는 방법과 거의 흡사하다는 것이 밝혀졌다.
좀 더 정교한 예를 들어보자. 고양이와 개의 사진이 있다고 하자. 그리고 이를 구분하도록 훈련된 신경망이 있다고 하자. 아래는 일부 예제들을 대상으로 어떻게 수행하는지를 보여준다.

이제 정답이 무엇인지 더 모호해졌다. 고양이 옷을 입은 개는 어떨까? 어떤 입력을 받아들이더라도 신경망은 사람이 하는 것처럼 일관되게 답을 만들어 낼 것이다. 앞에서 말한 것처럼 어떤 원칙을 통해 유추할 수 있다는 것은 사실이 아니다. 적어도 특정 도메인에서는 단지 경험을 통해 그렇게 보인다는 것을 알아냈을 뿐이다. 그러나 이것이 신경망이 왜 유용한지 중요한지에 대한 원인이 되기도 한다. 이렇게 하면 사람이 하는 것처럼을 잡아낼 수 있기 때문이다.
직접 고양이 사진을 들고 “이 사진이 왜 고양이일까?”라로 스스로 질문을 해보라. “글쎄 뾰족한 귀가 보이고 .. “와 같이 말하기 시작할 것이다. 그러나 왜 그 사진을 고양이로 인식했는지 설명하기가 쉽지 않을 것이다. 어쩌면 단지 두뇌에서 그렇게 인식했기 때문일 것이다. 그러나 두뇌 내부에서 어떤 일이 발생하는지 알아 볼 방법이 없다. 인공 신경망에서는 어떨까? 고양이 사진을 보여 줬을 때 각 뉴런에서 어떤 일을 하는지 직접 확인해 볼 수 있다. 그러나 일반적으로 기본적인 시각화를 하는 것도 매우 어렵다.
위의가까운 지점을 찾는 문제에서의 마지막 신경망은 17개의 뉴런을 사용했다. 손으로 쓴 숫자를 인식하는 신경망에서는 2190개의 뉴런이 사용되었다. 고양이와 개를 인식하는데 사용한 신경망은 60,650개의 뉴런을 사용했다. 일반적으로 60,650차원의 공간을 시각화 하는 것은 매우 어렵다. 그러나 이것은 이미지를 처리하기 위해 설정된 네트워크이기 때문에 pixel들의 배열처럼 뉴런으로 구성된 많은 Layer들이 배열(array)로 구성되어 있다.
전형적인 고양이 사진을 예로 들면

첫번째 Layer에서의 뉴런의 상태는 파생된 이미지의 묶음으로 표현할 수 있다. 이들 사진중에 많은 부분은 배경이 없는 고양이, 또는 테두리로 표현한 고양이 등으로 해석할 수 있다.

10번째 Layer정도까지 진행되면 어떤 것이 표현되고 있는지 알아채기 힘들다.

그러나 일반적으로 신경망은 어떤 특징을 뽑아내고(뾰족한 귀가 이들 중 하나일 수 있음) 이를 활용해서 이미지가 무엇을 나타내는지 결정한다고 말한다. 그러나 이들 특징들이 우리가 말하는 뾰족한 귀와 같은 것들일까? 대부분이 그렇지 않을 것이다.
우리의 두뇌도 이와 유사한 기능들을 사용할까? 대부분 우리는 알지 못한다. 그러나 앞에서 봤던 것처럼 신경망의 처음 일부 Layer는 개와 같은 이미지 특징을 뽑아낸다는 것에 주목할만 하다. 여기서 말하는 이미지의 특징은 두뇌의 시각처리의 최초 단계에서 뽑아낸 것과 유사하다.
그러나 신경망에서 사용하는 “고양인 인식 원리”를 찾는다고 하자. 그렇다면 이렇게 말할 수 있다. “자 보세요, 이곳 특유한 신경망이 그것을 수행합니다.” 그러자마자 이것이 얼마나 어려운 문제인지 암시해 줄 것이다(예를 들면, 얼마나 많은 뉴런과 Layer들이 필요한지). 그러나 적어도 현재로서는 신경망이 무엇을 하는지에 대해 설명할 수 있는 방법을 찾지 못하고 있다. 아마도 이는 computationally irreducible하기 때문일 것이다. 그리고 각 단계를 직접 추적하지 않고서는 내부에서 무엇을 하고 있는지 알아낼 수 있는 방법이 없다. 또는 과학을 아직 발견하지 못했거나 내부에서 어떤 것이 동작하는지를 요약할 수 있는 “자연법칙”을 확인하지 못했기 때문일 것이다.
ChatGPT를 활용하여 언어생성에 대해 얘기할 때도 이와 유사한 이슈를 접하게 된다. 다시말해 지금 하는 것을 요약하는 방법이 있을지에 대해서도 명확하지 않다. 그러나 풍부하고 섬세한 언어가 이미지로 가능했던 것보다 한단계 더 발전시켜 줄 것이다.